AI奇点网6月4日报道丨尽管亮相时被OpenAI压了一头,但谷歌一直在悄悄迭代Gemini大模型,和OpenAI最新大模型GPT-4o的差距已经显著缩小。

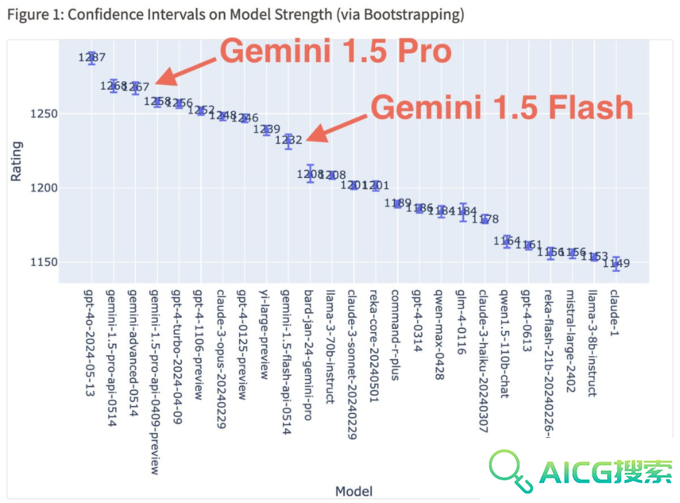
最新的大模型基准测评排行测试结果显示,Gemini 1.5 Pro/Advanced在综合测试中排名第二,逼近OpenAI的旗舰模型GPT-4o,轻量版的Gemini 1.5 Flash排名第9,已经超越了 Llama-3-70b,接近GPT-4。
相比4月份的版本,对用户免费的Gemini Pro和Gemini Flash的能力有明显加强。且上下文长度窗口的吞吐可以达到100万Token,远远超出GPT-4目前提供的12.8万Token,在实用性上领先。
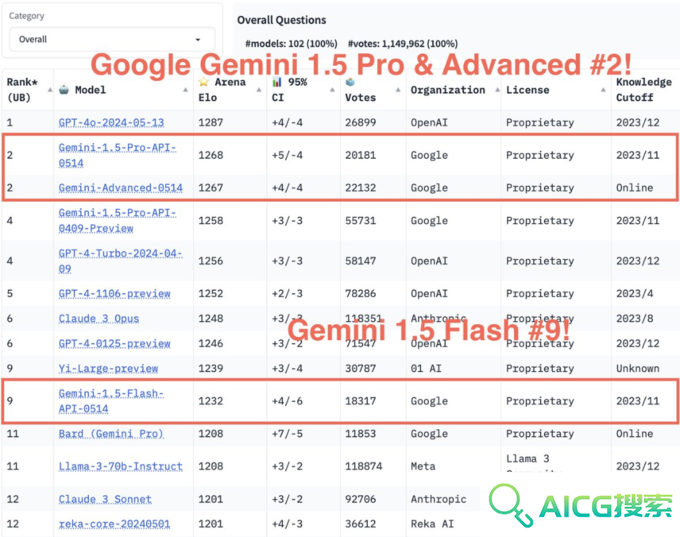
此外,谷歌Gemini的中文能力表现更是惊艳,在中文内容的测试中,Gemini Pro和Gemini Advanced双双超越GPT-4o,包揽了前两位。
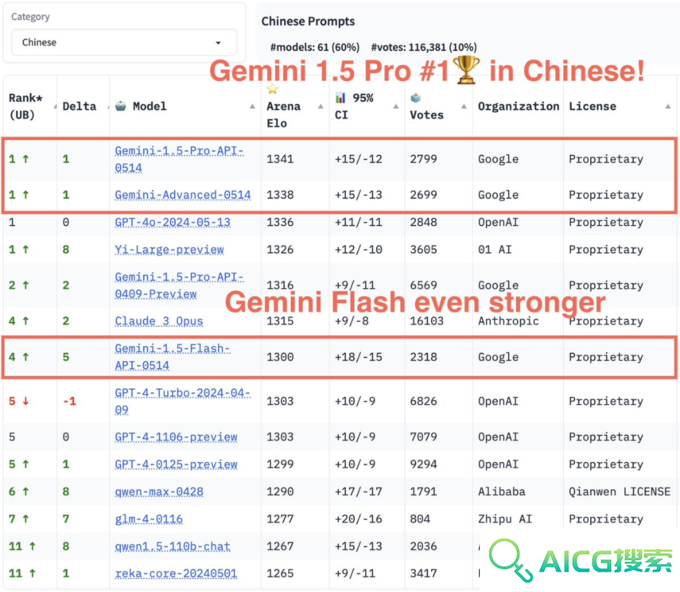
在针对复杂提示词「Hard Prompts」的测试中,谷歌Gemini同样名列前茅。在该专项挑战当中,大模型需要面对那些更具挑战性的问题,Gemini 1.5 Pro在测试中排名第二,仅次于GPT-4o。
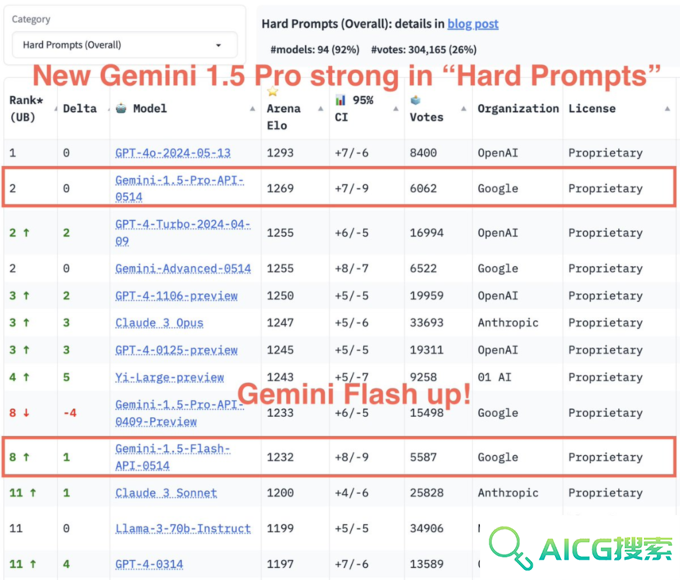
从大模型置信区间(Confidence Intervals)来看,Gemini的测试结果也名列前茅。
值得一提的是,就在两周前的I/O开发者大会上,谷歌Gemini更新再次撞档GPT-4o发布,被后期在舆情讨论热度上截胡。
而就在过去的数周内,谷歌Gemini因为羸弱的大模型推理能力几乎引来了群嘲。
根据多家科技博客的测评,即使谷歌已经对Gemini 1.5 Pro进行了数月的改进,但从常识推理到多模态能力和代码能力,仍然无法与OpenAI最新的GPT-4o模型相媲美。唯一亮点就是更大的长文本上下文窗口。
这次的测评结果显示,加紧进度“卷”模型能力的谷歌Gemini取得了如此神速的进步,显示出AI界“黄埔军校”仍然有深厚的技术底蕴。

 通义千问
通义千问 知料觅得
知料觅得 Stable Diffusion
Stable Diffusion DALL·E 2
DALL·E 2 AskCodi
AskCodi Lamini
Lamini 即时 AI
即时 AI Penelope AI,ai写作助手
Penelope AI,ai写作助手 PromptAppGPT
PromptAppGPT 访问电脑版
访问电脑版